Je viens de finir « Au commencement était… – Une nouvelle histoire de l’humanité », le dernier bouquin co-écrit par David Graeber. Un beau pavé, fascinant.
La thèse du bouquin en très court : historiquement, l’être humain est bien plus doué que ce qu’on pense pour inventer toutes sortes de systèmes politiques très différents les uns des autres. Les conditions matérielles ne déterminent pas les formes politiques. Alors retrouvons de l’inventivité !

Quelques notes
Déjà, c’est un livre épais. Je l’ai lu en plusieurs mois, tranquillou, chapitre par chapitre.
Ça vaut le coup : le bouquin explore plusieurs facettes des mêmes idées centrales, en les développant dans différents chapitres, époques et cultures.
Au début je ne voyais pas trop où il voulait en venir, mais ça s’est clarifié à force d’évoquer plusieurs la même chose de manière différente.
(Et aussi, pour les impatient·es, le résumé sur Wikipédia est très bien.)
La politique, déterminée par les conditions matérielles ?
L’idée de base, c’est que l’être humain a une grande inventivité pour créer des systèmes politiques et des manières de s’organiser.
Pas seulement à l’époque moderne : sans doute aussi loin que les preuves archéologiques remontent.
Plus on fouille les sites, plus on découvres les cultures humaines, plus on voit que y’a mille façons d’organiser des petits groupes, des villes, des aires culturelles entières.
Et le point important : tout ça sans déterminisme matériel, lié par exemple à l’économie ou à la taille du groupe.
-
Concernant l’économie/la production de nourriture, le bouquin cite des sites où l’agriculture se pratiquait non pas en continu, mais de manière intermittente, ou semi-annuelle. Pas parce que les gens ne savaient pas faire mieux : mais parce qu’ils préféraient comme ça.
Ou encore différents peuples de Californie du Nord, presque sur le même territoire, avec les mêmes ressources de poisson – mais ayant des organisations politiques radicalement différentes (par exemple libertaires ou esclavagistes).
-
Et sur le déterminisme de taille du groupe, le livre cite des fouilles archéologiques d’une ville de centaines ou milliers de familles. Cette ville a d’abord été sous des régimes très hiérarchiques, puis après un basculement très égalitaires (faute d’un meilleur mot).
Ou encore le cas une ville égalitaire, mais devenue très hiérarchique, puis qui a été abandonnée – entrainant un refus culturel des chefs trop puissants dans toute la région pendant les centaines d’années qui ont suivi.
L’agriculture, cause de l’État moderne ?
Mais pourquoi insister autant sur le refus du déterminisme matériel ? Pourquoi chercher à prouver que l’avènement de l’agriculture ou des villes n’entraine pas un mode politique unique (typiquement celui de l’État moderne) ?
Parce que c’est généralement le présupposé qu’on a tous en tête, depuis les Lumières.
C’est l’histoire classique de Rousseau : au début des petits groupes de chasseurs cueilleurs pouvaient bien être égalitaires. Et puis bim, on découvre l’agriculture, et sans même qu’on s’en rende compte, cette découverte entraine la propriété, les excédents, l’administration centrale, les riches, l’État, l’inégalité. C’est mathématique. L’État et les inégalités, c’est l’aboutissement du progrès, c’est comme ça.
Sauf que, dit le bouquin, c’est historiquement faux.
La marche vers l’État moderne n’est pas linéaire, elle n’est pas déterminée. En tout cas c’est ce que le livre s’attache à prouver, à travers plein d’exemples.
Par exemple, que les peuples n’ont pas été « pris au piège de l’agriculture » : ils l’ont pratiqué de manière non-permanente pendant des millénaires, sans doute justement pour ne pas y adjoindre les désavantages de la sédentarisation. On trouve beaucoup de traces d’agriculture pratiquée seulement quelques mois dans l’année, ou quelques temps avant un déplacement. Et ce n’est pas que les gens ne savaient pas s’y prendre : ils choisissaient consciemment de ne pas pratiquer une agriculture permanente.
Ou encore, qu’on peut avoir des villes de taille importante qui soient auto-organisées – ou pas. Mais il n’y a pas de déterminisme là dessus : une ville n’est pas forcément hiérarchique, c’est un choix.
Caractériser plus finement la notion d’État
Autre sujet abordé par le bouquin : la question de l’émergence de l’État.
Essentiellement, c’est pour dire que la question n’a de sens que si on considère l’État comme quelque chose qui doit émerger, dans un processus historique. Et qui reste là une fois qu’il a émergé (sauf effondrement de civilisation).
À la place, les auteurs préfèrent un découpage plus fin de ce que c’est qu’un « état ». Ils voient trois points :
-
La souveraineté : la tête a-t-elle le pouvoir de faire respecter ses décisions là où elle n’est pas ? Typiquement via la violence légitime
-
La bureaucratie : il y a-t-il une administration centrale et un contrôle de l’information efficace ?
-
La concurrence charismatique : les potentiels leaders politiques mettent-ils en scène des luttes/jeux entre eux ?
À partir de là, ils utilisent plein d’exemples historiques pour montrer que des systèmes politiques peuvent comporter un, deux, ou trois de ces éléments de domination de l’État. Et parfois avancer sur la voie d’un État, mais parfois aussi revenir à quelque chose de plus vivable.
Les Lumières, inspirées par les réflexions indigènes
Il y a aussi des passages passionnants sur la manière dont certaines idées des Lumières sur l’égalité se sont formées à partir de la critique contemporaine des indiens d’Amérique. Ceux-ci, dans les décennies après la conquête, découvraient le fonctionnement européen – et avaient parfois un avis très clair dessus.
Si ce point vous intéresse, je vous recommande Wikipédia pour un résumé – ou une pré-publication de ce chapitre disponible en accès libre : La sagesse de Kandiaronk : la critique indigène, le mythe du progrès et la naissance de la Gauche.
En bref
Je ne donne que ce que j’ai compris des principaux arguments – mais en vrai, l’ensemble des descriptions d’exemples historiques sont très chouette à lire, et argumentent bien le propos.
C’est vraiment quelque chose que j’apprécie bien dans l’archéologie et l’anthropologie : lire des exemples d’organisations radicalement différentes de la nôtre – et se dire qu’on pourrait bien en faire tout autant.
Bref, conclusion de tout ça : ne restons pas bloqués dans la forme de l’État moderne, recommençons à inventer plein de choses ; mais si, c’est possible.
Among all the powerful abilities of Ruby Enumerators, one of their most useful usage is to customize what gets enumerated.
For instance, by default #each will yield the elements of the enumeration, one by one:
array = ["apple", "banana", "grape"]
array.each do |value|
puts "${value}"
end
# "apple"
# "banana"
# "grape"
In some cases, however, we may also need the index of the element being enumerated.
For this, we can use Enumerator#with_index. It turns an existing enumerator into one that also yields the index:
array.each.with_index do |value, index|
puts "${index}: ${value}"
end
# "1: apple"
# "2: banana"
# "3: grape"
The neat thing: this works for any enumerator! For instance, if you’re not enumerating using #each, but rather using #map or #filter, the usage is the same:
array.map.with_index do |value, index|
"${index}. ${value.uppercase}"
end
# ["1. APPLE", "2. BANANA", "3. GRAPE"]
How to craft your own enumerator helpers
Recently, I wanted to enumerate the pixels of an image.
The pixels are represented a single-dimensional array of integers:
image.pixels
# [998367, 251482, 4426993, 777738, ... ]
However, in my case, I want to perform different operations depending on the pixel coordinates.
Of course, we can compute the coordinates in the loop itself:
pixels.map.with_index do |pixel, i|
x = i % image.width
y = i / image.width
pixel * ((x + y) / 100.0) # brighten from top-left to bottom-right
end
But there has to be a better way. What if we could substitute the enumerator’s .with_index by something like .with_coordinates?
First, I needed a quick refresher on how to write a method that enumerates on values. AppSignal’s article on Enumerators was quite a good read there.
So, our method just needs to yield the values one-by-one, and that’s it? Let’s try this.
We’re going to re-open the Enumerator class, and add a #with_coordinates(width, &block) method:
class Enumerator
def with_coordinates(width, &block)
each.with_index do |value, i|
x = i % width
y = i / width
yield value, x, y
end
end
end
When called, Enumerator#with_coordinates will invoke its block once for each of the enumerator values - passing the coordinates along.
Let’s see how it is used:
pixels.map.with_coordinates(image.width) do |pixel, x, y|
pixel * ((x + y) / 100.0) # brighten from top-left to bottom-right
end
The coordinates computation are pushed away from the block, the code is nicer… Good job.
Plus, #with_coordinates works not only for #each, but for any enumerator – juste like #with_index!
Method chaining on enumerators
There’s only one caveat though: in Ruby, enumerators support method chaining.
That is, instead of passing a block to the enumerator, we can instead call methods on it. Like this:
pixels
.each
.with_index
.with_object("filename.png") do |pixel, i, path|
puts "Pixel at #{path}:#{i} => #{pixel}" if i = 5
end
# "Pixel at filename.png:5 => 1962883"
But if we try this with our current implementation of Enumerator#with_coordinates, we get:
pixels
.each
.with_coordinates(width)
.with_object("filename.png") do |pixel, x, y, path|
puts "Pixel at #{path}:#{x}:#{y} => #{pixel}" if x == 2 && y == 2
end
# in `block in with_coordinates': no block given (yield)
# (LocalJumpError)
Makes sense: our helper yields to a block, but Ruby complains that none was provided.
To fix this, we need to return an Enumerator instance when our #with_coordinates function is called without a block.
Let’s modify our implementation of Enumerator#with_coordinates:
class Enumerator
def with_coordinates(width, &block)
+ if block_given?
each.with_index do |value, i|
x = i % width
y = i / width
yield value, x, y
end
+ else
+ Enumerator.new do |y|
+ with_coordinates(width, &y)
+ end
end
end
end
And there we have it: using the block-less form will return a new Enumerator.
pixels.each.with_coordinates(width)
# <#Enumerator: ...>
Which means we can properly chain #with_coordinates with further methods now:
pixels
.each
.with_coordinates(width)
.with_object("filename.png") do |pixel, x, y, path|
puts "Pixel at #{path}:#{x}:#{y} => #{pixel}" if x == 2 && y == 2
end
# "Pixel at filename.png:2:2 => 1962883"
And that concludes our short side-quest on implementing Enumerator helpers in Ruby. It feels very expressive; and I like how we can make our custom helpers as powerful as the native ones.
Happy enumerating!
To become a better developer, they say, read a lot of code. Although we, as a profession, often find more enjoyable to write a hundred lines of code rather than read ten, this advice stands more than ever. So let’s explore some codebases, starting with Rails applications.
Last june, 37signals released a new product, Writebook – free of charge, and full source code included. An excellent occasion to see how the company that initiated Ruby on Rails writes code.
I’ve downloaded and run the app, explored the source code, and took some notes. Here are my takes on this code base.
What is Writebook
Writebook is a web app for publishing book-like content on the web. Books supports pages composed in Markdown, sections separators, and full-page pictures.
Writebook’s presentation on 37signals website will show you how the app looks like, and what it does. I recommend you to have a short look at this presentation, to know what we’re talking about – then come back to this article.
How to obtain the code
Writebook is free, but its code is not truly open-source. You are allowed to read the code, and to make modifications, but not to publish them, or to re-use part of the code in another product.
This means the code is not hosted in a public repository (for instance on GitHub). Instead, once you “purchase” the application (for free), you get access to a zip file containing the full source code.
Exploring the code
The stack
- Rails, directly on the trunk
- Database: SQLite
- Webserver: Puma
- Templating: ERB
- Javascript: propshaft, import-maps, Stimulus
- Tests: Minitest
Models
Controllers
-
Controller methods are reduced to their shortest expression. Most action methods are only a few-lines long:
class BooksController < ApplicationController
def index
@books = Book.accessable_or_published.ordered
end
def new
@book = Book.new
end
def create
book = Book.create! book_params
redirect_to book_slug_url(book)
end
-
To support these short controller methods, many pre-checks are extracted to callbacks:
class BooksController < ApplicationController
before_action :set_book, only: %i[ show edit update destroy ]
before_action :set_users, only: %i[ new edit ]
before_action :ensure_editable, only: %i[ edit update destroy ]
Some of them are further extracted into concerns – like UserScoped, BookScoped, which contain methods like before_action :set_user, etc.
-
No model validations means that most controllers simply use exception-throwing methods (like update!), and propagate the exception in case of invalid data. There’s no need to handle the failure case explicitely, which helps to make the methods shorter.
My take: I wonder if this approach of simplifying all controller code by removing error handling is workable in larger-scale apps. Maybe letting the browser handle required fields and formats is sufficient, but I’m not fully conviced yet.
Views
- Templating language used: ERB.
- Accessibility gets quite some attention: there’s
aria attributes, a for-screen-reader CSS class, and so on.
- Views are cached using the
cache directive.
- Many views make a liberal use of
content_for, for configuring :title, :head, :header, :footer, and so on.
- Icons are displayed using small SVG files (that may be colored using CSS and the
filter property).
- The Markdown editor is based on
ActionText, but doesn’t use Trix (ActionText’s defaut editor). Instead, it uses House, a new internal editor from 37signals. The editor is vendored as a single vendor/house.min.js file.
CSS
- Language used: plain CSS (no SCSS or similar things).
- Stylesheets closely matching a single component use a loose BEM syntax (like
assets/product.css).
- But stylesheets for more global layout are more a mixed bag of classes,
:has rules and :is scopes (see assets/pages.css).
:has is used everywhere. allow_browser versions: :modern is used to restrict access to browsers that support it.- Dark-mode is implemented.
Javascript
- Framework used: Hotwire (Turbo, Stimulus)
- No Javascript bundler; all import maps.
- There is quite a lot of Javascript: around 20 Stimulus controllers, some of them quite meaty.
- A lot of custom code too. For instance, re-organizing pages using drag-dropping is a fully custom implementation (
arrangement_controller.js, a ~250 lines Stimulus controller). No external library is used for the drag-n-drop code.
- Use of “modern” Javascript facilities: lot of
async, #privateMethods, and so on.
Turbo
- Quite a lot of turbo-frames, used to refresh small form elements (like the “Publish” toggle).
- A handful of manual turbo-streams; mostly to add, move or delete pages.
- Page updates are broadcasted to all editors using
Turbo::StreamsChannel.broadcast_render_later_to, to add a small “This page is being edited by another editor” indicator on the page. The code to support this in leafables_controller.rb is surprisingly small.
Design
- The design language feels quite nice. It recalls Basecamp: round buttons, horizontally-centered controls, few borders and mostly plain-page aligned elements.
Tests
- Test framework: Minitest
- Test data are generated using static YML files in
test/fixtures (rather than factories)
- The app is well tested, but there isn’t a ton of test either. Most of them are model tests, and controller test (as
ActionDispatch::Integration) tests.
- Only two system tests, for testing editing a page and publishing a book.
- Many tests use the
assert_changes and assert_difference helpers.
- Test cases are surprisingly short and concise. I guess preloaded fixtures really help there.
test/test_helper.rb is also very short, almost no configuration.
- A handful of files look extracted from other 37signals applications. I’m thinking about
concerns/positionable.rb (implements a list with customized ordering), the authentification and session code, things like this.
-
There is not a single comment in the code. None. The only comments are in Rails-generated boilerplate.
My take: it looks like that the general philosophy is to have methods and variables named sufficiently clearly to make comments unnecessary. I disagree: sometimes why the code does something can’t be captured by naming alone.
-
Authentification and sessions don’t use any external gem (like devise). Instead the app declares its own SessionsController and AuthenticationConcern. The actual Sessions are stored in a dedicated database table.
My take: the code of this authentication infrastructure is surprisingly light and clear – but non-trivial nonetheless. I guess the benefits of writing your own code is that you don’t pay the price for the full configurability and extra levels of indirection of an external library.
- The source files tend to push complexity outward. Something becomes hairy? Move it to an external concern, or a Rails framework extension. This is probably also how Rails is built: by pushing into Rails the complexity of 37signal apps.
Conclusion
I’m amazed by the terseness and concision of the code base. Methods are short, and don’t leak complexity everywhere. That said, there’s a real business complexity in some parts: digging in the complexities of the Leafable model or the drag-dropping Javascript code can take a while. Short code isn’t always easy to read, but it feels simple, and not overwhelming.
The terseness of the code also comes from the use of Rails by Rails creators. They know the framework by heart, use it to the maximum, and push code to the framework when needed. After reading this code base, I think more of Rails as 37signal’s public web framework.
This codebase also embodies Rails as a one-person framework: a single developper, knowing the inside of the framework perfectly well, can write an ambitious web app using all the available resources Rails has to offer.
Next, I consider exploring other large Rails codebases: GitLab, Mastodon, maybe others. Let’s see where it goes.
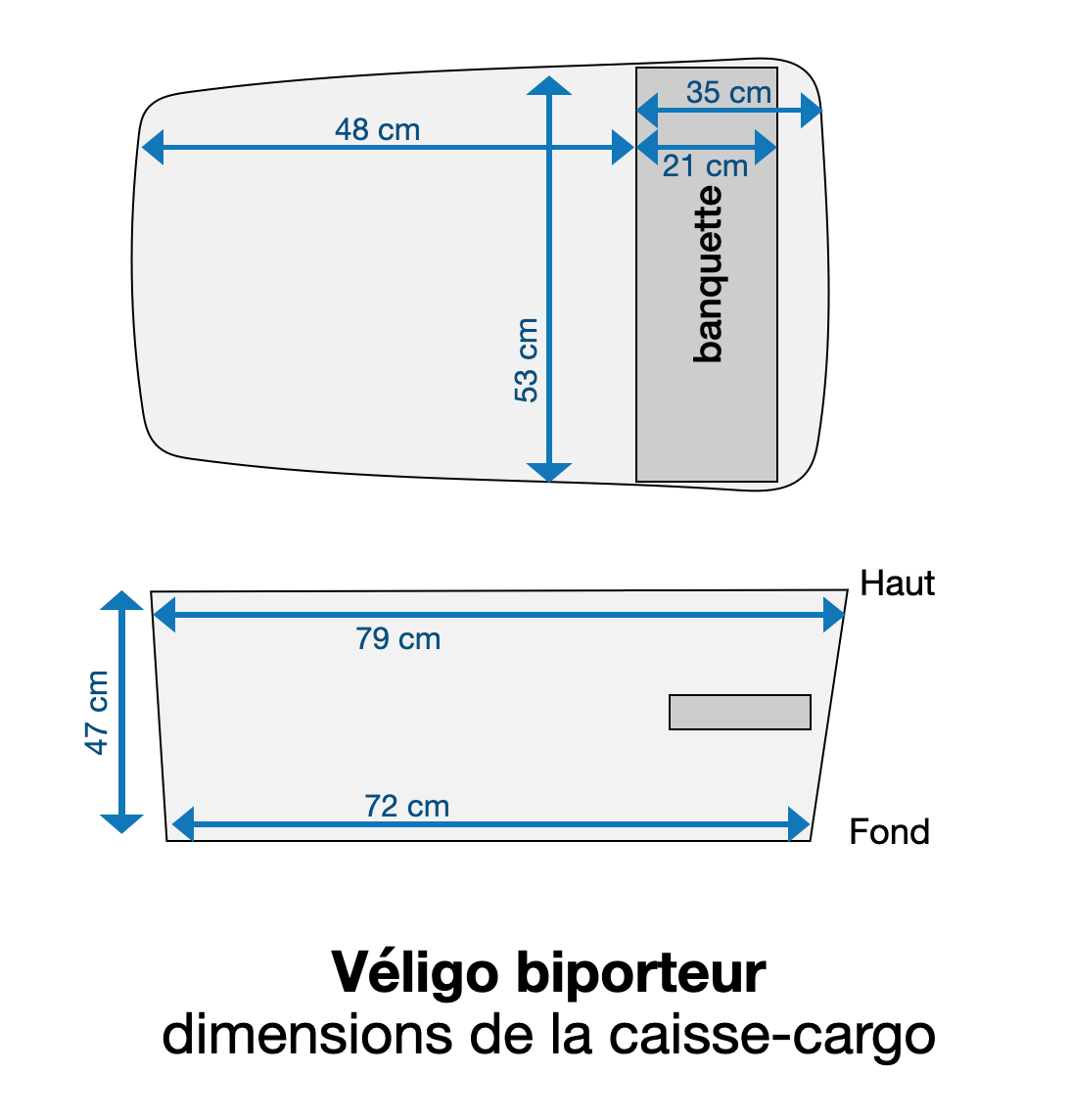
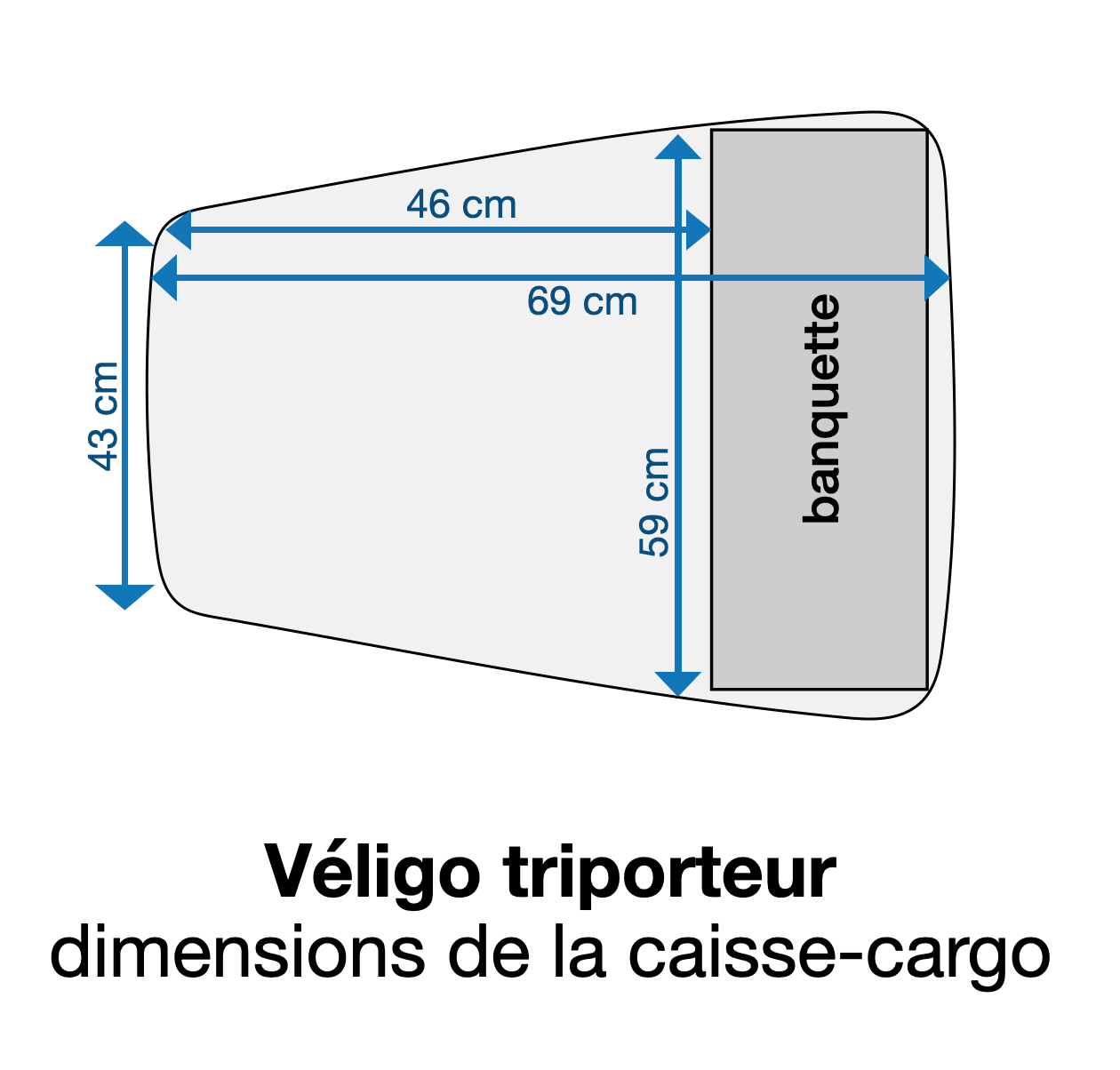
En cherchant un siège-enfant qui rentre dans un Véligo cargo, je me suis rendu compte qu’il était difficile de trouver en ligne les dimensions précises de la caisse de chaque vélo (biporteur ou triporteur).
Voici donc les relevés des dimensions de chaque caisse.
Véligo biporteur

Véligo triporteur

After two years of waiting, a new progress report for the Zelda: Link’s Awakening disassembly is finally published!
To celebrate this, I took the time to move this series of articles to its own dedicated website: the Link’s Awakening disassembly blog. Of course, the former URLs now redirect to these new pages.
This move makes subscribing to new disassembly-related articles easier, since only relevant Link’s Awakening content will be published.
And meanwhile my own blog will resume to more random and personal stuff.